
ファイルをサーバーにアップロードする従来のオンラインPDFエディターとは異なり、当社のエディターはJavaScriptを使用してブラウザ内ですべてをローカルに処理します。これは、あなたの文書がデバイスから離れることがなく、最大限のプライバシーとセキュリティを保証することを意味します。
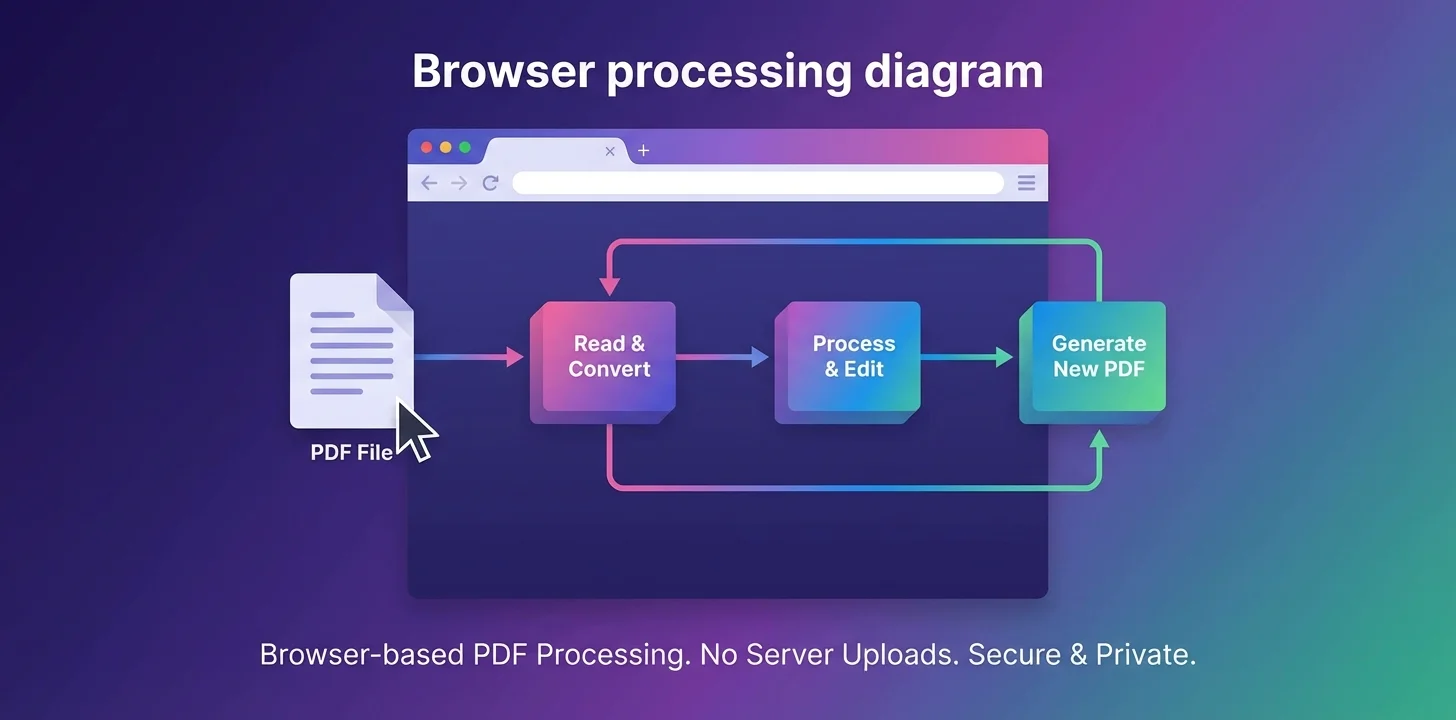
ローカル処理の仕組み
ページを読み込む
当社のウェブサイトにアクセスすると、ブラウザはエディターを動かすHTML、CSS、JavaScriptコードをダウンロードします。これは一度だけのダウンロードで、読み込み後はエディターは完全にオフラインで動作できます。
技術詳細: 標準的なブラウザAPIを使用して、ローカルファイルシステムからメモリに直接ファイルを読み込みます。これはデスクトップアプリケーションで使用されているのと同じ技術ですが、ブラウザ内で実行されます。
ファイルをアップロード
ファイルを選択またはエディターにドラッグすると、ブラウザのメモリ(RAM)に読み込まれます。これは完全にあなたのデバイス上で行われます - ファイルはどのサーバーにも送信されません。
技術詳細: 標準的なブラウザAPIを使用して、ローカルファイルシステムからメモリに直接ファイルを読み込みます。これはデスクトップアプリケーションで使用されているのと同じ技術ですが、ブラウザ内で実行されます。
ブラウザ内で処理
すべての編集操作 - 結合、切り抜き、回転、注釈 - は、ブラウザ内で実行されるJavaScriptコードによって行われます。ドキュメントの解析とキャンバス操作のために強力なオープンソースライブラリを使用しています。
技術詳細: 当社のライブラリはPDFドキュメントを解析してレンダリングし、キャンバスライブラリは編集機能を提供します。すべてはWebAssemblyとJavaScriptを使用して完全にクライアントサイドで実行され、最適なパフォーマンスを実現します。
結果をダウンロード
「ダウンロード」をクリックすると、編集された文書はブラウザのメモリ内で生成され、デバイスに直接保存されます。繰り返しますが、当社のサーバーからアップロードもダウンロードもされません。
技術詳細: メモリ内で出力ファイルを生成し、ブラウザのネイティブダウンロード機能をトリガーします。ファイルはブラウザからファイルシステムに直接送られます。
従来型 vs. ローカル処理
従来のサーバーベースエディター
- 1.ファイルがサーバーにアップロードされる
- 2.サーバーがファイルを処理して保存
- 3.編集されたバージョンをダウンロード
- 4.ファイルがサーバーに残る可能性がある
プライバシーリスク:文書が外部サーバーを経由し、保存される可能性があります。 文書が外部サーバーを経由し、保存される可能性があります。
当社のローカルブラウザ処理
- 1.ファイルがブラウザのメモリに読み込まれる
- 2.ブラウザがローカルで処理
- 3.デバイスに直接ダウンロード
- 4.オンラインに痕跡が残らない
100%プライベート:文書がデバイスから離れることはありません。完全な機密性。 文書がデバイスから離れることはありません。完全な機密性。
ローカル処理がより安全な理由
データ漏洩の可能性ゼロ
ファイルが当社のサーバーに到達することはないため、サーバー侵害、ハッキング、データ漏洩で公開されるリスクはゼロです。サーバーにないものはサーバーから盗まれることはありません。
不正アクセスなし
私たちがアクセスしようとしても、文書にアクセスすることはできません。文書はブラウザの一時メモリにのみ存在し、タブを閉じるかページを更新すると自動的にクリアされます。
コンプライアンス対応
GDPR、HIPAA、その他のプライバシー規制の対象となる文書の取り扱いに最適です。データがデバイスから離れないため、報告やセキュリティ対策が必要なデータ転送や保存がありません。
オフライン動作
ページが読み込まれれば、インターネットを完全に切断しても編集を続けられます。これにより、最大限のセキュリティのための真のエアギャップ編集が可能になります。
文書の追跡や分析なし
どのファイルを編集したか、何ページあるか、どんな内容かは分かりません。当社の分析は匿名のページビューのみを追跡し、文書の内容やメタデータは追跡しません。
自動クリーンアップ
ブラウザタブを閉じるかページを更新すると、すべての文書データがすぐにメモリからクリアされます。何も残りません、キャッシュも一時ファイルもありません。
技術実装の概要
技術的な詳細に興味がある方のために、当社のエディターが内部でどのように動作するかを説明します:
PDFの解析とレンダリング
オープンソースのブラウザライブラリを使用してPDFドキュメントを解析します。解析はJavaScriptとWebAssemblyを使用してブラウザ内で完全に実行され、サーバーの支援なしにテキスト、画像、ベクターグラフィックを抽出します。
キャンバス操作
切り抜き、回転、注釈などの編集操作には、強力なHTML5キャンバスライブラリを使用します。すべての描画と操作は、ブラウザ内の<canvas>要素で行われます。
画像処理
HEICからJPGへの変換は、ブラウザAPIとJavaScriptライブラリを使用します。画像は、Canvas APIと専用コーデックを使用して、メモリ内で完全にデコード、処理、再エンコードされます。
ドキュメント生成
PDFをダウンロードする際、ブラウザベースのライブラリを使用してメモリ内でPDFファイルを構築します。画像エクスポートでは、Canvas APIを使用してページをレンダリングし、JPG/PNG形式に変換してからZIPアーカイブにパッケージ化します。
これらのライブラリはすべてオープンソースで監査可能です。データを他の場所に送信する可能性のある独自コードは使用していません。すべてが透明で検証可能です。 データを他の場所に送信する可能性のある独自コードは使用していません。すべてが透明で検証可能です。
主張を検証する方法
技術に詳しいユーザーの方には、ローカル処理について私たちが真実を述べていることを検証することをお勧めします。方法は以下の通りです:
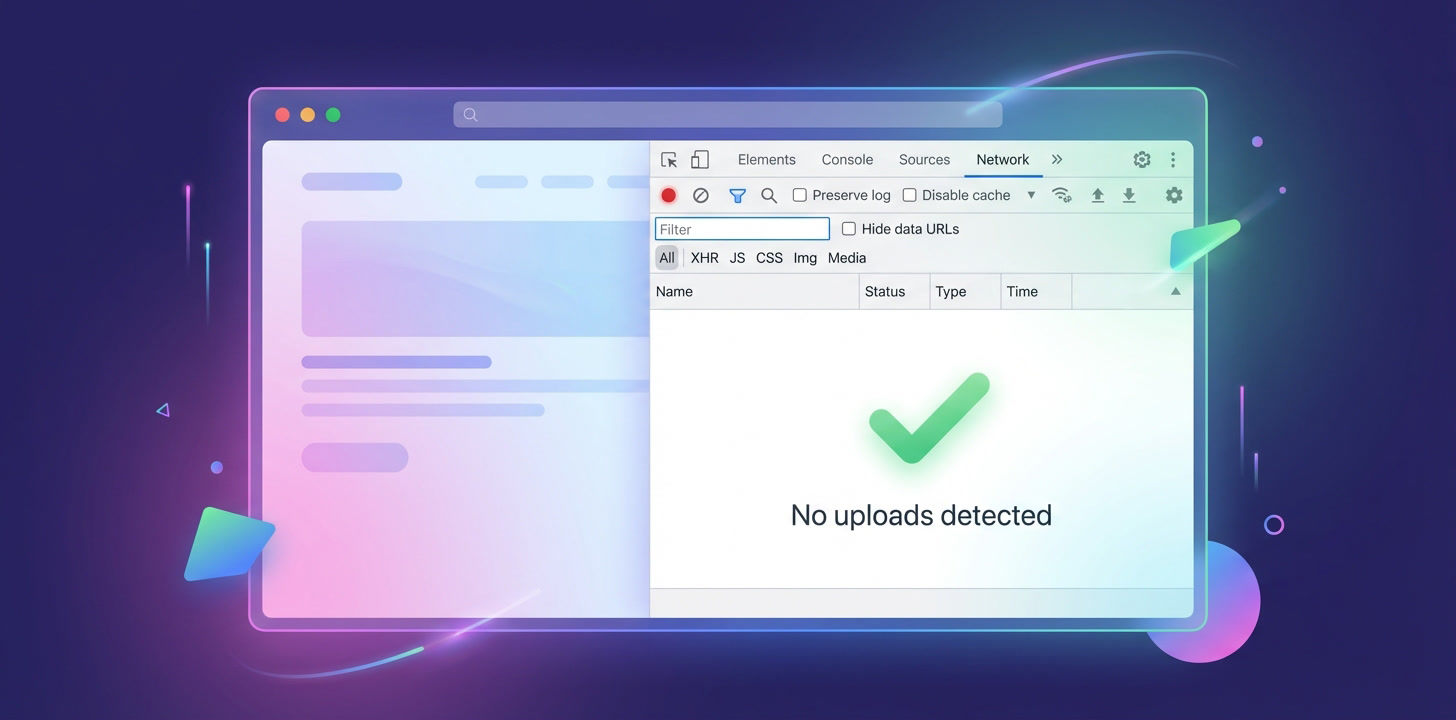
方法1:ブラウザ開発者ツール
- 1. 当社のウェブサイトを開き、F12を押して開発者ツールを開く
- 2. 「ネットワーク」タブに移動
- 3. エディターにファイルをアップロード
- 4. ネットワークアクティビティを確認 - ファイルのアップロードリクエストは表示されません
- 5. サーバーから読み込まれるのは最初のページリソースのみ
方法2:オフラインテスト
- 1. ブラウザで当社のウェブサイトを読み込む
- 2. インターネットから切断(WiFiをオフにするかイーサネットを抜く)
- 3. 文書をアップロードして編集 - すべて機能します
- 4. 結果をダウンロード - オフラインでも機能します
- 5. これはサーバー通信が不要であることを証明します
方法3:ソースコード検査
当社のJavaScriptソースコードはブラウザに配信され、検査できます。ドキュメントデータを含むネットワークリクエストを探してみてください - 見つかりません。すべてのファイル操作は、ローカル処理用の標準ブラウザAPIを使用しています。
機密文書に最適

当社のローカル処理アプローチにより、機密文書の取り扱いにエディターが最適です:
結論
ローカルブラウザ処理は単なる機能ではありません - 根本的なプライバシー保証です。文書をデバイス上に保持し、ブラウザ内で完全に処理することで、オンラインドキュメント編集における最大のセキュリティとプライバシーリスク、つまりファイルを第三者に委ねることを排除します。
私たちは決してあなたの文書にアクセスできないため、文書を私たちに委ねる必要はありません。これはポリシーによるセキュリティではなく、設計によるセキュリティです。